
Batch processes are integrations that handle multiple documents or records in a single execution, processing them collectively instead of individually in real-time. Batch processes work with groups of data (documents, records, or transactions) rather than handling them one by one immediately.
The integration process may retrieve multiple documents or a single document containing multiple records from the source system. Consider an FTP folder or a disk location where multiple files need to be picked up and sent to the target system. Similarly, consider an AS2 endpoint receiving an EDI 850 document containing multiple transaction sets. In both scenarios, the process must handle and process multiple records.
Avoid these 6 mistakes in your Boomi Batch Integrations (and How to Fix Them!)
❌Not designing the integration for partial processing of documents
The integration should be capable of partial processing of documents. A document can fail for the following three reasons
a) Connector exceptions because of network issues, connector configuration issues or timeouts
b) Bad parameters passed during the connector call resulting in error responses
c) Document data is evaluated using decision or business rules shape for mandatory values and reported for errors.
When the document hits any of the above exceptions, the standard practice is to fail the execution and report the error in the process reporting page. Boom’s Exception shape serves this purpose.
For Exception step to stop only error documents and continue processing others, each document that reaches the exception shape should have a unique document ID.
If the connector emits multiple documents, the runtime assigns distinct document ID to each document. However, if the connector emits a single document with an array of records, you might split them to process to target system. In this case, all the split documents would be assigned the same document Id. To ensure each split document receives an unique ID, introduce a try catch shape which resets all document ids with an unique one.
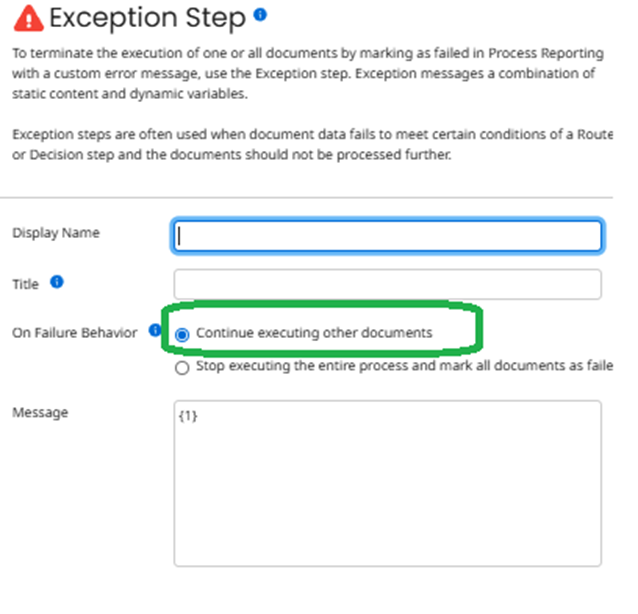
Additionally, leave the exception shape’s default 'On Failure Behavior' set to 'Continue executing other documents,' which ensures only the failed documents are stopped.
Please see below a Try/Catch is introduced after Data Process shape splitting PO to assign unique IDs to split documents.

Exception Step with On Failure Behavior set to “Continue executing other documents”
❌ Ignoring Aggregated Error reporting
It is possible that multiple documents can fail for different error reasons, and it will be beneficial to display a combined error message in the “Error Message” column of the process reporting portal.
Please see below the error message where error messages pertaining to multiple documents are concatenated and displayed in the error message.

To achieve this, a canonical structure with four fields document Id, failure point, status and status message needs to be mapped and added to cache at all failure points.

The final step in the process is to retrieve all canonical documents, concatenate the error messages if any, and terminate execution using an exception step.

Alternatively, the error messages captured can be formatted into tabular report and emailed to interested recipients.
❌Running each document individually
The Flow Control Step with “Run each document individually” processes one document at a time in all the subsequent steps. This will be particularly useful when a batch of documents needs to be processed in a specific sequence such as FIFO.
Consider an integration processing a batch of shipment status messages from the TMS system, the status messages need to be processed sequentially as FIFO based on date/time of the shipment messages. In such cases, the documents can be sorted based on shipment status datetime and then sent to the customer system in sequence using Flow Control Step with “Run each document individually” batch option. Since this option runs only one document at a time, it slows down the process and it should be used sparingly.
In most cases, there will not be a need to process documents in sequence but processes them a group. Boomi works at its best when batches of documents are processed in each step. Design and build the integration process efficiently using dynamic document properties and Document Cache shapes to process batch of documents than using “Run each document individually” flow control option.

❌Not leveraging sub process to regroup documents
As said earlier, Boomi integration process works optimally and has better processing speed when groups of documents are processed in each step. However, the grouping can break when the documents are processed through decision, branch, route steps as the documents are separated and processed along the respective route paths.
For example, in decision step "true" documents are processed to completion before the "false" documents are processed. Also, the route shape processes documents to each of its route paths separately. To reunite documents, identify places where document batching is lost and group them in a sub process with a return shape. Documents that reach the return step are batched as it executes only after all paths in the process are complete.
Grouping documents is vital when processing EDI documents. The trading partners expects identical transaction sets to be enveloped into a single Functional Group/Interchange. The Trading Partner Send shape requires batch of documents to be able to successfully group and envelope them. In such situations, subprocess with return step plays a key role in retaining the document batching so that Trading Parter send shape properly packages the raw EDI.
Please see below main process and a subprocess with a return shape to group documents after a branch shape,


❌Rerun not enabled for reprocessing
Documents can fail during processing because of connection issues, during data validation or bug in the code. In such cases, it is required to reprocess the failed ones after the connectivity issue is resolved or fixing the code. To successfully reprocess a document, the process Start step should be a connector.
If an array of documents comes from the source system, it is required in most cases to split and process the documents. If one or few documents fail and the rest goes out successfully, it is NOT possible to selectively resend the failed documents as the Start Step has a single document with an array of records and rerunning the single document would resend all once again.
One of the options to manage this is to place the split document in an intermediary staging location such as local folder or Event Streams or Atom Queue etc and have a second process receive and process them. The Second consumer process would start with a start step and processes a batch of documents. If one or more documents fail, the failed documents can be individually processed without issues.
Please see below an execution where the rerun option is available as the process is configured to Start with a connector shape

❌Extended logging for error documents
When a document encounters error during processing, the document data is required for troubleshooting purposes. Documents that are processed through connectors are stored and can be viewed in processing reporting. However, connector operations can store either input or output documents and NOT both.
To access the other document that is NOT tracked by the connector, a Notify shape can be used to log the content. It is important to note that the Notify shape can log up to 10000 characters and anything beyond that would be truncated. To overcome this limitation and to effectively log the document data, introduce notify shapes on the error/catch paths thereby logging only the error data.
In the below screenshot, the notify shape logs the document content when the status code is NOT 204 indicating an error. Success documents are NOT logged.

Should you have anything more to add, please write in comments
Comments